Amazon S3 is an object storage service provided by Amazon Web Services (AWS). Companies across the world turn to Amazon S3 to store files and data objects in a highly available and flexible cloud service. Data security is of paramount importance whether your team stores data in S3 or some alternative service. How your team implements data security in S3 is quite different how data is secured in alternative cloud services or on-premise infrastructure.
Below we discuss some of the best practices that for securing data in S3.
Basic S3 concepts
To understand how to use these security best practices you must be familiar with some basic concepts related to S3.
- Amazon S3 stores data in logical storage units called buckets. An AWS account can have any number of buckets. A bucket stores objects. An object is a file that is stored in a bucket. A unique key identifies an object inside a bucket.
- There is no hierarchy of folders inside an S3 bucket. All the objects are stored in a flat structure. But, S3 lets you emulate a folder hierarchy with special keys that end with ‘/‘.
- An access point is a network endpoint attached to a bucket. You can use access points to execute operations on objects stored in a bucket.
The security principles described here, secure the data by restricting access to buckets and objects and auditing the user activities on them.
Amazon S3 Security Best Practices
#1: The principle of least privileges with security policies
The principle of least privileges is a basic requirement for data security. When considering the principle of least privilege, your team must only grant legitimate users to access your S3 buckets and the objects inside. For these users, you must grant only the minimum required IAM permissions to satisfy the business objectives.
You can implement this principle of least privilege by establishing security policies. These security policies let you define who has access to your resources and what they can do with those resources.
There are two types of security policies; bucket policies and IAM/user policies.
Bucket policies
A bucket policy defines what actions can be performed on buckets and objects, irrespective of an AWS IAM user. As an example, you can restrict access to a bucket and objects based on AWS account, source IP address, or AWS service. Teams should consider restricting bucket access to only necessary cloud services and entities.
IAM/User Policies
User policies let you set access control standards for your S3 resources within AWS IAM users and groups.
S3 security policies are robust and flexible to implement very fine-grained access control. You can control access to a bucket as a whole, or individual objects inside a bucket. You can also define access control based on S3 emulated folders.
To ensure security for your S3 resources, you must first restrict all access to buckets and objects with bucket and user policies. Then, you can grant specific privileges for individual users and objects as required. S3 policies are defined in JSON format using AWS access policy language. This JSON format lets you implement even very complex access control requirements.
#2: Access restrictions with ACLs
Network ACLs can be utilized to supplement S3 security policies and implement additional access restrictions. You will be able to implement 99% of your access restrictions using bucket and user policies. But, there are certain use cases where ACLs must be used.
For example, you may allow a user in a different AWS account to upload files to a bucket in your AWS account. In this case, you may configure additional ACLs to set access permissions for the objects that this user uploads. ACLs are defined in XML. ACLs allow you to grant basic read/write permissions to other AWS accounts. You should consider using ACLs for use cases where policies cannot be used.

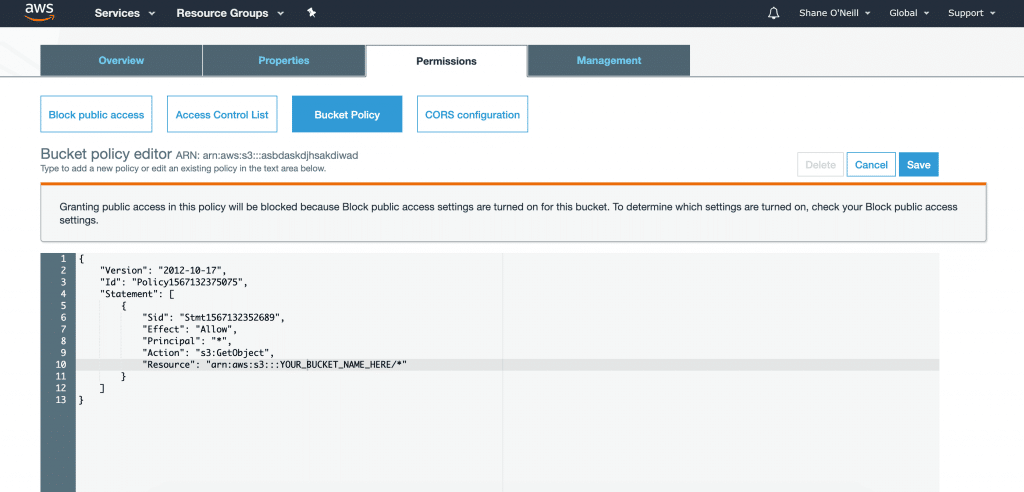
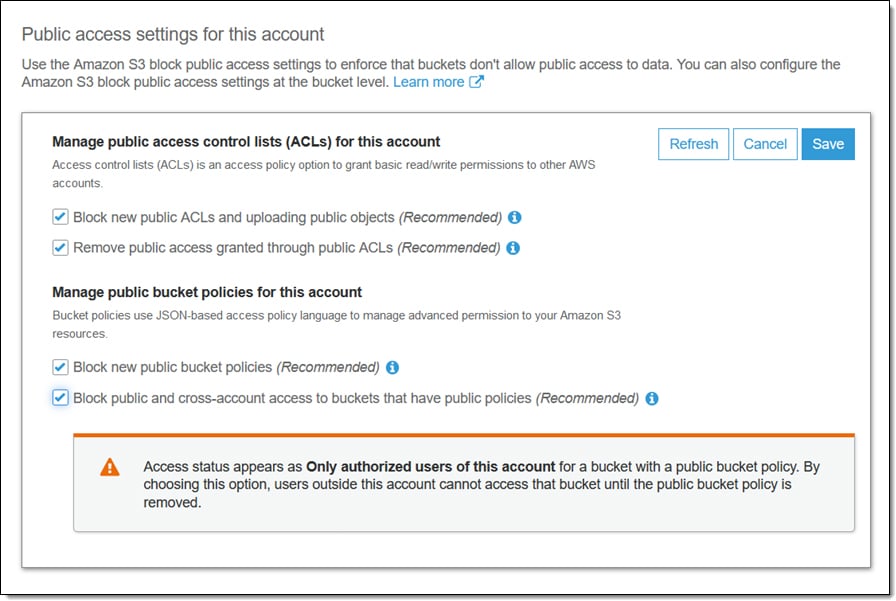
#3: Block public access for all new buckets
While some of your S3 buckets may need to be publicly accessible (IE. making specific files available to the web), most S3 buckets should have restricted access. It is recommended that your team enables global settings for restricting bucket “public access” and then grants public access individually to only those buckets that specifically require it.
To enforce this behavior, you should enable options related to ‘S3 Block Public Access” in the AWS management console. With these settings enabled, by default all new S3 buckets created in your account by any user will not be publicly accessible. In addition, your team van block new public ACLs that may provide public access to a bucket.
These settings can help your team prevent your S3 buckets from being exposed to the public due to human errors. For the specific buckets that require public access, you can grant this access separately.
#4: Use AWS PrivateLink for S3
Depending on your AWS infrastructure and cloud services, you may want your applications running in Amazon VPCs to access S3 objects. AWS PrivateLink is a feature that allows organizations to securely facilitate this access without going through the public Internet.
AWS PrivateLink lets you provision interface endpoints for S3, inside the VPC. Then, applications in VPC can use these endpoints to access the objects stored in S3. With VPC peering, your applications in a different AWS region can also privately access these S3 resources.
By using this service, you can expose applicable S3 buckets to your private applications without making these buckets publicly accessible.
#5: Use server-side encryption
No matter how tightly you enforce access controls, there is a possibility that a malicious user may find a way to access your data. To add another layer of protection, your team should consider enabling S3 object encryption in order to limit unauthorized access to data by a 3rd party.
S3 uses AES-256, one of the strongest block ciphers, for server-side encryption. When you enable server-side encryption for a bucket, S3 encrypts each object stored in the bucket. Data is decrypted for permitted and authenticated users. Your team should consider enabling this server-side encryption for each S3 bucket in your AWS environment.
#6: Use client-side encryption
While server-side encryption secures your data stored in S3, client-side encryption provides an additional layer of encryption while data is in-transit. Client-side encryption allows your team to secure application data. Client-side encryption safeguards can help you guard against data loss and unauthorized access to data.
Amazon offers a software library, AWS encryption SDK for client-side encryption. Teams should consider using this SDK in your software applications to encrypt data before transferring it to S3.
#7: Monitor with CloudTrail
Audit logging is an important component of data security. In order to detect suspicious behavior or spot security incidents, your team should continuously monitor and audit user activities related to S3 buckets.
CloudTrail from AWS is a service that can be utilized monitoring and auditing. CloudTrail monitors user activities and AWS API usage and generates events. Each CloudTrail event is a record that contains all the information about a certain action executed by a user and its outcome. It also includes information such as users and accounts, source IP, time, etc.
CloudTrail has three types of events; management events, data events, and insight events. To monitor S3 buckets and objects you must enable data events.
By monitoring your S3 buckets and objects with CloudTrail, you can gain complete visibility of what your users are doing with the data stored in S3. You can use this information to uncover potential threats and fix them before an actual attack materializes.
#8: Use GuardDuty to automate log analysis
When you enable CloudTrail data events for S3 buckets and objects it can generate a very high volume of records. Manually analyzing them could be time-consuming and impractical.
Amazon GuardDuty is a service that can help you automate this log analysis. It has a special feature to analyze the CloudTrail data events for S3. When GuardDuty detects a threat based on these events, it generates a security finding. Based on these findings, you must take appropriate corrective actions to improve security in your S3 buckets and objects. Consider enabling AWS GuardDuty and connecting CloudTrail events to this service to better detect security incidents.
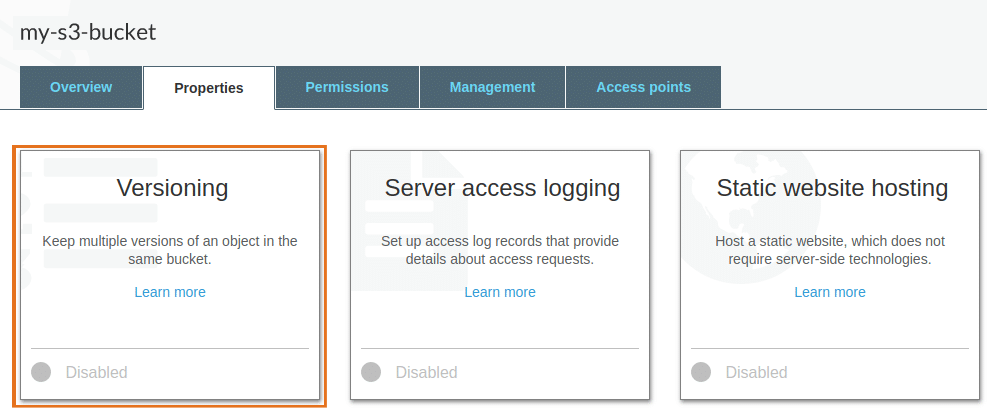
#9: Enable S3 versioning
Data security practices should protect organizations from data loss that could occur from application issues or human error. Consider the following – A legitimate user could accidentally delete an entire S3 bucket. A misbehaving application may corrupt a set of data rendering it useless. Versioning S3 objects protects your data from such unintended behaviors of legitimate users and applications.
When you enable versioning, S3 keeps multiple versions of each object in the bucket. Each time you upload an object with the same name, S3 stores a new version of the object. Similarly, when you delete an object, S3 retains the copy but inserts a delete marker to the latest version of the object. S3 uses a version ID to keep track of these objects. If the latest version of the object is corrupted, you can recover your data from one of the older versions.
S3 does not impose any restrictions on the number of versions you can keep for each object. You can use the object expiring feature to delete older versions of an object. Alternatively, you could implement your own mechanism for object life cycle management.
Security teams should consider enabling versioning for all S3 buckets and creating a object lifecycle where applicable.
#10: Enable MFA delete
Your team should consider enabling Multi-Factor Authentication (MFA) to add an additional layer of protection for S3 buckets. Security credentials with users can be compromised. One way to guard against unauthorized use of user credentials or keys is to enable MFA.
You can enable MFA for object deletion operations in version-controlled buckets. When deleting an object in buckets with this setting, you must provide an authentication code generated by an MFA device. You can use either a hardware or a virtual MFA device for this purpose. Consider requiring MFA for object deletion to better protect S3 bucket data.
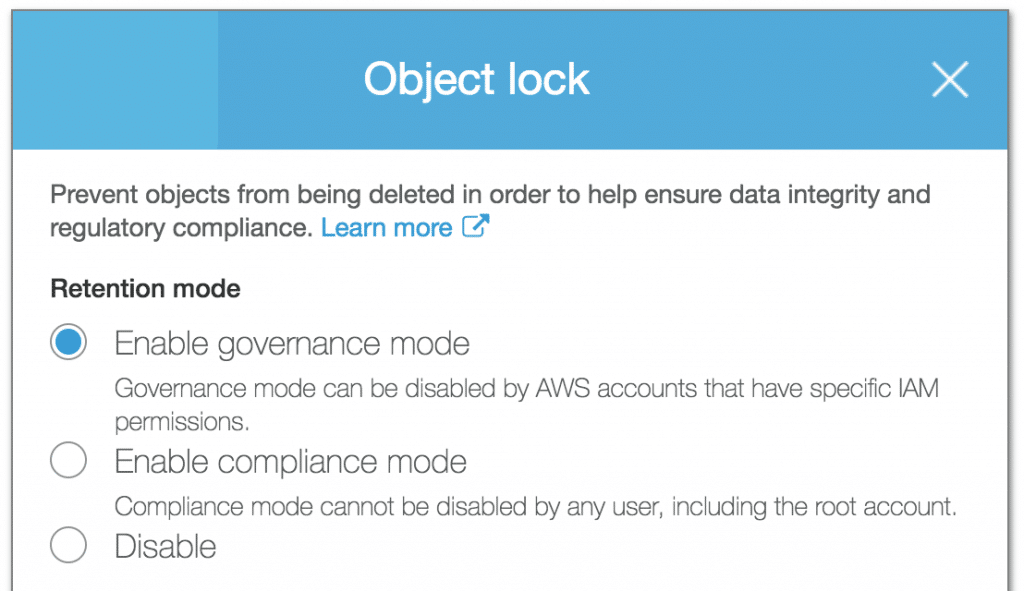
#11: Use object lock for read-only objects
There are certain objects that you may write once and read many times. Object lock provides a way for your team to protect such objects from accidental deletion or overwriting. Before enabling Object Lock you must enable versioning for a bucket, before locking an object.
There are two modes of object lock:
Governance mode
Users with specific permission can delete or override an object in governance mode. The other users can only read this object.
Compliance mode
Any user cannot delete or override an object in compliance mode. The object lock is removed after a configured retention period.
You may enable one of these modes based on your requirements in order to protect S3 objects and ensure that data is not changed. Consider enabling these options for buckets and objects containing audit logs and information that should not be modified.
Conclusion
Amazon S3 is a powerful service, that provides an easy way to store and access large sets of data and files. Teams can utilize S3 to build highly available cloud applications, but should be sure to configure all necessary security settings related to S3 buckets, objects, and connected entities. Security teams may turn to a solution such as Dash ComplyOps to automatically monitor, and resolve security issues within their AWS cloud environment.
In this guide we have provided some we have described some security best practices for utilizing S3 and related security features. By following these best practices you can improve your data security in S3 and improve your overall cloud security posture. For further questions about security and compliance in AWS, feel free to reach out to the Dash team.